As many cloud-enabled organizations optimize their cloud infrastructure for the applications, keeping them resilient is one of the most important aspects for cloud operations and SRE teams. When organizations move more and more workloads, cloud environments increasingly become complex and adopting cloud provider best practices for shared Virtual Private Cloud networks (VPC) is key. At Appranix, we have seen several VPC models across multiple clouds. Understanding these shared VPCs is key from application infrastructure deployments to regular operations to application resilience for achieving business continuity.
Dynamic Ever-changing Cloud Environments
From the moment you choose your cloud foundation, VPC architecture continues to evolve to accommodate several applications. Whether they are migrated with lift and shift or created natively using serverless cloud services. Application infrastructure continues to evolve dynamically based on the complexity of your application and organizational requirements. Multiple devops pipelines with hand coded cloud infrastructure to automated configuration management to third party system management tools, all dynamically change what’s on the shared VPCs and make them extremely complex. These complexities exacerbate application resilience with backup and recovery of all the resources in the shared VPCs.

Shared VPC models and application environment recovery complexities
We all wish there was a single straightforward approach to deploying and managing VPCs. Also, it is a wishful thinking that every customer follows the best practices given by the cloud providers. We have seen customers creating a single VPC and using all the applications running in the same cloud account. We have also seen applications logically separated out by separate cloud accounts and several VPCs within those accounts. Every model presents a unique challenge to provide application resilience with varying complexity.
Google Shared VPCs
Google cloud has a very flexible model. For more details, refer to — https://cloud.google.com/vpc/docs/shared-vpc. These shared VPCs allow for easy communication between platforms and services for applications. They are also easier to manage with various deployment teams. The complexity is when applications or components of the applications need to be recovered in another region of the cloud. Is it possible to properly replicate the same configurations from the source project to the target region? How much effort does it take for common SRE teams to understand the complexities and be confident to be able to recover for business continuity?

From application resilience perspective, some of the biggest problems are: keeping the same ip addresses between the services, adjusting the firewalls, routes, and making sure the DNS entries are appropriately configured after the recoveries. These issues are particularly complex when applications cross the boundaries between GKE based Kubernetes namespaces and GCP based platform services, such as CloudSQL, BigQuery or other serverless services.
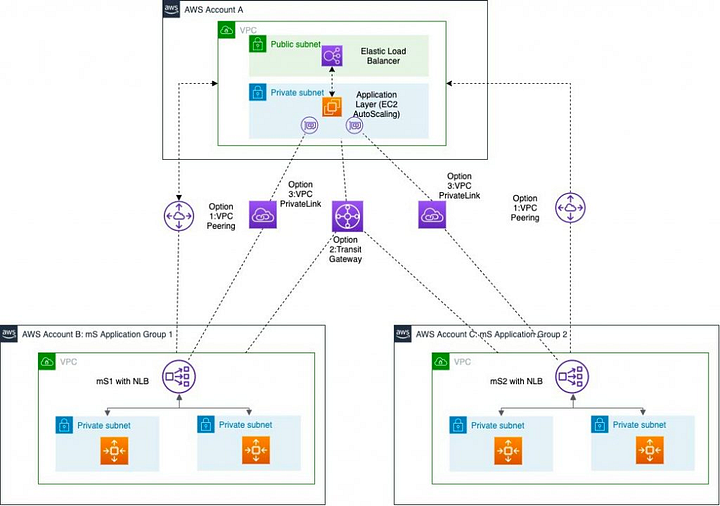
Sharing VPCs in AWS and Recovery Complexities
Appranix actively discovers 100s of AWS accounts within an enterprise. They are segmented per their application needs, reducing operational complexity and future environment expansions. For example, software-defined storage systems might be configured in a separate VPC so storage teams can manage independently. Centralized hub accounts have VPCs with all the system management services such as monitoring, backup, security products. Lot of enterprises still maintain their data centers with direct connection to the VPCs where the shared application services connect to each other.
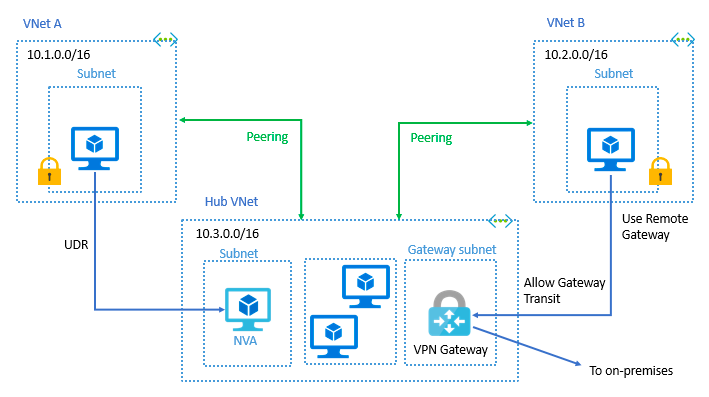
Azure vNets and Disaster Recovery
It is important to understand Address Space, Subnets, Regions and Azure Subscription best practices when dealing with Azure vNets. Refer — https://docs.microsoft.com/en-us/azure/virtual-network/virtual-network-disaster-recovery-guidance. There is a lot of flexibility to be able to configure based on your application requirements and service interactions.
Azure best practices suggest what to do when a region becomes completely inaccessible due to a natural disaster, or a partial disaster or several services disruptions. Shared vNets particularly complicate the recoveries and a lot of enterprise deployments are very complex.
Recovering applications spread across multiple vNets connected by peering is particularly complex when a partial or full disaster happens.
What about application data?
Along with discovering application cloud resources for protection, it is needless to say how important it is to protect all the application data in-sync with environment resources for successful system recovery. Cloud platforms offer one of the best ways to make copies and move them to different regions or even continents. You could also protect your data in more than two regions as well. One obvious choice is your production region, another is a failover region in the same continent, and perhaps a region in another continent for the third level of data resiliency. However, keep in mind that every copy you maintain is going to cost you in cloud dollars. So it is important to keep your backup and replication policies based on the number of data copies you must really need.
Taking the headache out of cloud-native DR with shared VPCs
Achieving cloud application resilience for your dynamic ever-changing application environments needs a great level of understanding of your shared VPCs. You don’t have to toil your way out of the complexity while managing everything else. Appranix Cloud Application Resilience system offers a simple, yet comprehensive way to deal with all kinds of complexities in your network.

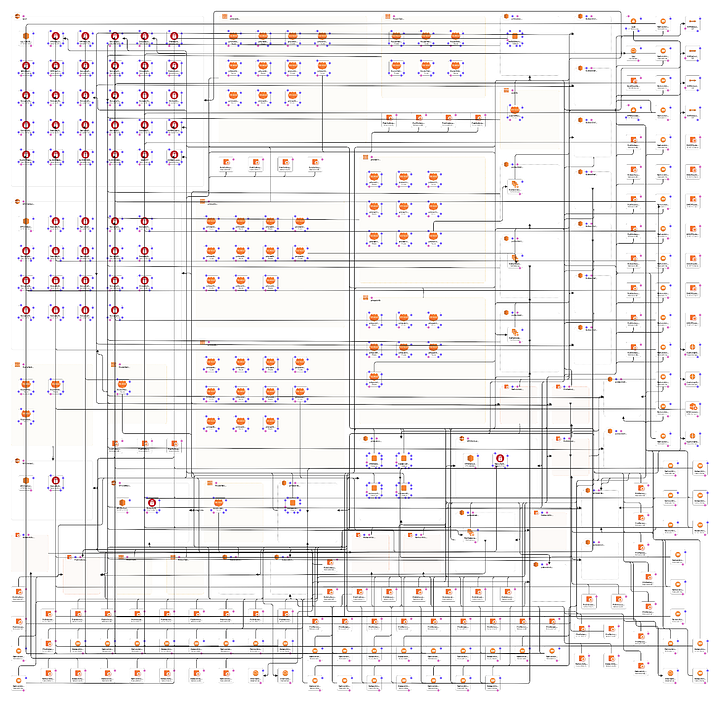
Over the years, we have seen many complex networks across the multi-cloud spectrum. Our solution has recovered very complex large applications with 100s and 1000s of resources with dependencies that even internal teams have struggled to understand. One of our latest recovery tests involved 100s of applications with 2000+ resources and 1000s of dependencies spanning many nested Infrastructure-as-Code templates. Appranix service makes this all possible with a single click.
Complex dependencies based cloud VPC infrastructure like the following run 100s of applications for enterprises that need their business to be close to “Always-on”. Every downtime costs not only money but precise engineering time that could be doing valuable updates to your applications. Appranix takes all that headache out of the complexity and recovers or failover your applications to another cloud region rapidly to reduce your business downtime.
Get in touch with us to work with your shared VPC environments