Organizations have rapidly shifted to a decentralized operating model for cloud applications. Software architectures have become more distributed using easily accessible cloud resources. Distributed teams are able to run environments with thousands of resources easily with fewer operations teams. They also have moved to more dynamic and faster release cycles using DevOps practices to accommodate customer requirements. On the negative side, though, all these changes have caused enormous problems for the shared operations service teams that are responsible for resilience, security, and cost. In addition, programmable cloud resources have enabled auto-scaling of environments to accommodate the performance requirements of critical business applications. The biggest question now is how these dynamic, auto-scaled, ever-changing application environments can be properly protected for recovery from downtimes!
Why is the legacy BCDR model, well, just legacy?
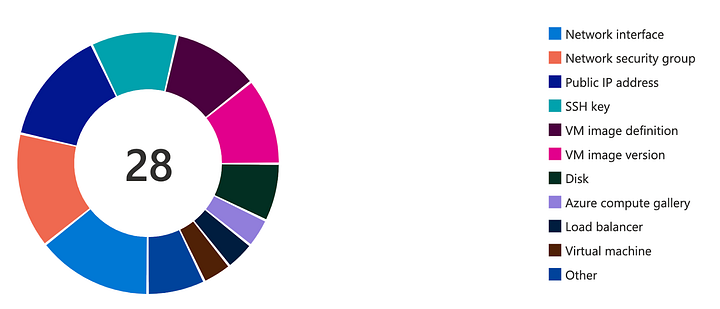
Applications do not rely on a few servers and single most important databases any longer after moving to the cloud. Consider a simple three-tier Azure application below with a scale-set with two virtual machines and a database. It relies on a minimum of twenty-eight (28) different cloud resource instances. Legacy backup and recovery systems were not designed to protect these dynamic, distributed applications that are scaled-in or scaled-out as the performance requirements change. They can not even discover all the cloud resources properly, forget about protecting them.
How’s Ransomware changed application recovery requirements
While most of the backup and recovery vendors offer some form of recovery from Ransomware attacks, these systems offer only limited capabilities to recover entire application systems. As mentioned an application system is made up of multiple cloud infrastructure services running many components of an application system. Legacy BCDR systems need a tremendous understanding of these application systems by cloud operations teams to be able to piece together virtual machines, databases, and other associated cloud resources to recover them properly. Moreover, key components of the network such as virtual private networks, load balancers, gateways, security groups, database parameter groups, etc, need to be manually assembled ahead of time by the cloud operations teams before even engaging with BCDR systems.
In fact, as most of the BCDR products are installed in the primary domain cloud account as that of production systems if a Ransomware attack takes over the entire account, it is not even possible to even reach the consoles of the backup and recovery systems to be able to recover the application environments.
It is important to build an immutable meta-data repository of all critical cloud application environments in a completely different system or even in a different cloud for better resiliency. In this model, central cloud operations teams can recover entire environments despite a production cloud region is inaccessible due to a cyberattack, achieving a much better cyber resilience.

Continuous discovery of cloud resources is key to better resilience
Dynamic and auto-scaled cloud environments introduce enormous challenges to the centralized cloud operations teams to keep them secure and resilient. As development teams self-service the majority of the cloud infrastructure, cloud environments expand at a faster pace. These ever-changing environments need a system to continuously discover all the resources that belong to an application. Organizations also have many cloud accounts to isolate their development, production, and test environments depending on their business needs. 100+ accounts for a large enterprise cloud user is not uncommon.
The complexity of many cloud accounts along with fast-changing environments makes it really hard for centralized teams to rely on traditional, non-application-centric protection and recovery systems as these systems simply rely on users to pick the right resources and manually apply protection for their applications. They constantly struggle to identify the resources to protect. Application developers do not know all the cloud infrastructure resources used for their applications so they are unable to help the SREs as well. You need a system that continuously discovers and is application-centric and should have the capability to understand the system resources using automated dependency mapping to properly protect all the relevant cloud resources. It is then possible to appropriately failover the applications, data, configurations, state, and dependencies to another region easily.

The importance of Infrastructure-as-Code (IaC) for recoveries
The most complex part of recovery is identifying the right compute, storage, networking infrastructure resources corresponding to a set of applications and sequencing them for an orchestrated recovery. This is called a “Technical DR Plan”, TDP for short. There is also a non-technical aspect of the DR plan which concerns bringing human and other organizational resources for application validation after the recoveries.
TDPs are typically multiple pages and need several operational people working together to identify what runs in production, in terms of configurations, dependencies, sequencing, and scripting. There are products like VMware Site Recovery Manager or Azure Site Recovery that were created for the data center era. Organizations that have used these legacy products will tell you how complex TDPs are and why they don’t run recovery tests often. Take a look at the picture below to see why organizations struggle with recovery tests.
It is now possible to completely eliminate manual TDPs with an automated infrastructure-as-code (IaC) model. In particular, for guaranteed recoveries, it is important to use cloud-native IaC, instead of a cloud-neutral IaC so the responsibility of running large system recoveries shifts over to the cloud provider with dynamically scalable resources to be able to complete the recoveries successfully during a downtime.

Cloud-native Data Copy Management
Cloud platforms have enough data management capabilities to be able to make much faster data copies for backup, replication, and recovery. There is no need to add any additional data management capabilities from third-party vendors. There is no need to change the data storage format from native application storage data to a common data backup format and go through the lengthy process of import and export into the neutral backup file system. It is possible to make forever incremental data consistent copies from virtual machines and databases to reduce the cost of backup, and DR. Serverless services have enough built-in data management capabilities to avoid costly copying to and from data management platforms bolted onto a cloud environment.

Appranix Cloud Application Resilience service takes advantage of all the cloud-native data infrastructure capabilities to deliver a solid data management solution even for demanding workloads at a cloud-scale.
Cloud Application Environment Time Machine
Cloud Time Machine is a simple concept in which an automated system can assemble all the app-centric cloud resources’ meta-data in an immutable database for point-in-time recovery. You could imagine these time machines as CMDBs that are automatically refreshed from an application-centric perspective using all the cloud-native capabilities. However, the most important difference between a Cloud Time Machine compared to the older CMDBs is that it knows about the point-in-time data copies for the applications. Over time a cloud time machine becomes invaluable for organizations as multiple groups within an organization can readily tap into it for various rollbacks, recoveries, and failovers. Legacy BCDR systems never gathered meta-data of systems to be useful beyond simple data backup requirements.
There is nothing wrong with that approach but for cloud applications, they are less useful as the cloud platforms have enough data infrastructure capabilities for basic data management. Now you have the opportunity to use all the latest innovations on the cloud and solve some of the nagging resiliency issues that were not solved before.
Summary
The dynamic nature of the cloud applications, whether they were created natively on the cloud platforms or migrated from the data center, really need a new application-centric resilience as opposed to the legacy ways of backup and recovery or disaster recovery. Now, organizations not only have the choice of leaving their traditional recovery systems on-prem but also have the choice to increase the resilience of their applications tremendously using services like Cloud Application Resilience.
Book a time for a quick demo to see what you can do with a Cloud Application Resilience system. 15 mins of your time could save hours of your application downtime! — Book a Demo