If you are reading this blog, it means that you are one among the crowd of people trying to simplify Disaster Recovery (DR) Plans for your cloud application environments so your IT systems can recover from downtimes. COVID-19 pandemic has reinforced the need for better business continuity plans for your software systems. As companies continue their cloud-bound journey for their digital transformation efforts, business continuity models are transforming as well with a much more active approach of using application resilience models. The most challenging job is creating a DR plan runbook that is valid and relevant as cloud application environments continuously change. As applications become more and more cloud-native, they are becoming more distributed and complex every day. Creating and maintaining a DR plan runbook using legacy tools and approaches will not work on the cloud platforms.
“Let us change it manually now!!!”
“Let us do it now and modify it later!!!”
Familiar phrases? To a certain extent, the cloud flexibility and few Infrastructure-as-Code utilities like Terraform has allowed few of you to think that cloud infrastructure can be protected easily using the GitOps approach. You can certainly, always falsely assume that your infrastructure is what you have coded and checked into the repository lately. The complexity of handling the configuration drift and setting up an auditing process to make sure who changed what and why without updating the IaC will be an unanswered question, because when the team focused on making sure the application is running during an outage will least consider changing the IaC and keeping it updated at the time of emergency bug fix or a critical product release that requires an Infrastructure upgrade.
“The Data can be recovered easily from my cloud platform snapshots!!!”
Really!!! Look at yourself in the mirror twice, if you have this phrase in your mind and you are the one handling a DR runbook for your company. Let’s do a simple calculation. Let’s say you have 100 virtual machines running in your production VPC. Each of the virtual machines has at least one additional data disk attached to it, other than the OS disk. Let’s have configured a schedule to take snapshots for all your VMs every one hour (RPO of 1 hour) with 24-hour retention. So you will be having 200 snapshots at the first hour and at the end of one day, you will be having 200 * 24 = 4800 Snapshots. How hard can it be to bring up your specific 200 snapshots belonging to a particular point in time and specific your systems using a particular version of the infrastructure as code to make sure all your application components work just like before? When did you try doing it last time?
“The Escape Route!!!”
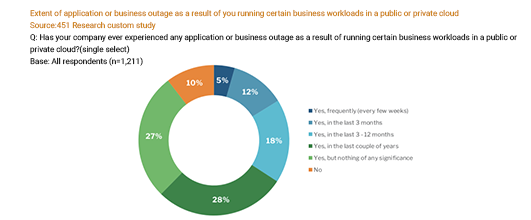
We cannot escape a DR plan for sure, but we can make sure your DR plan is simple and is testable, and very importantly you can be confident and peaceful even after any downtime. According to the latest 451 research, only less than 15% of organizations frequently test their DR plans.
How about a system that can automatically generate your DR plan using an infrastructure-as-code model by continuously reverse engineering your infrastructure and with an automated data lifecycle management?
Easily meet your stringent RPO and RTO requirements using a SaaS platform created from the ground up for your cloud applications. Redefine your business continuity plans and achieve better Cloud Application Resilience so you can sleep better!
Give Appranix SaaS a try on the AWS Marketplace or the Google Cloud Marketplace.