Overview
As containers became the standard for creating modern applications or modernizing existing applications, Kubernetes (K8s) has become the de-facto standard for running them at scale and in production. Kubernetes has gained momentum with a very large community support including support from backers like Google, Amazon, Microsoft, IBM, Red Hat and many other large enterprises and SaaS companies. Cloud Native Computing Foundation (www.cncf.io), the maintainers of Kubernetes, fosters a large eco-system of add-ons and associated platforms. As of this writing, there are 22,000+ contributors to CNCF, chief among them is for Kubernetes and its eco-system.

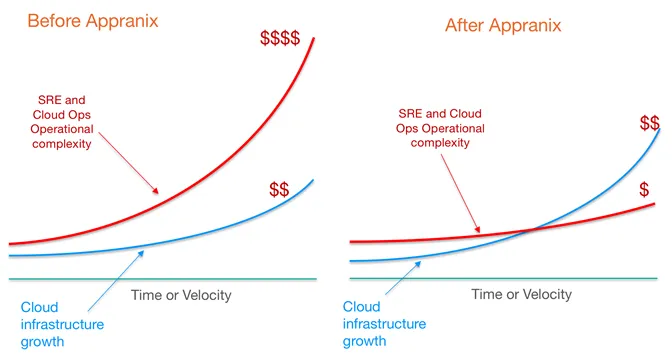
The evolving powerful capabilities of K8s and eco-system bring enormous complexity for businesses to set up and operate various parts of the system and keep up with the changes almost on a weekly if not daily basis. This white paper offers details and viewpoints of how a Do-it-Yourself approach to Kubernetes deployment and management could become expensive if organizations are not careful in laying the right management foundation. It is easy to get started for Site Reliability Engineering or cloud operations teams with an initial configuration of the cluster on cloud IaaS platforms such as AWS EC2, Google Cloud or Azure or VMware but on-going manageability becomes unsustainable. This paper also gives specific details of how businesses can benefit from Appranix Site Reliability Automation platform with capabilities to deliver, protect and optimize large multi-cluster K8s environments on multi-cloud environments. Enterprise Management Associates has ranked Appranix as one of the Top 3 platforms for running containers at scale and in production using Kubernetes (https://www.appranix.com/resources/case-study/ema-analyst-report.html)Laying the right container infrastructure management foundation for the modern cloud-native applications will immensely pay back over the long run besides getting the initial deployments completed in a matter of hours instead of weeks or months.
Industry Views on Kubernetes Complexity
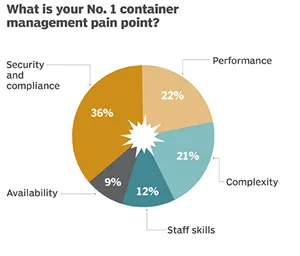
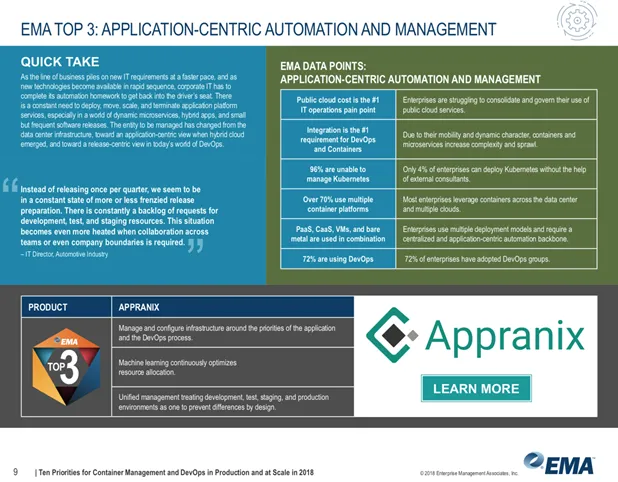
There are several hundred articles on Kubernetes with topics ranging from benefits, complexities, and support to eco-system of vendors and their support platforms. The entire DevOps movement and cloud native application development are also inextricably tied to Kubernetes. CNCF community is very responsive and active with fast paced releases of the core platform and add-ons ranging from monitoring, logging, networking, storage, service management and security, etc. DevOps and cloud operations teams have been trying out various versions and combinations of the add-ons. Figure 2. Shows the results of a recent survey by Enterprise Management Associates from 301 enterprise users of containers and Kubernetes, and their pain points.
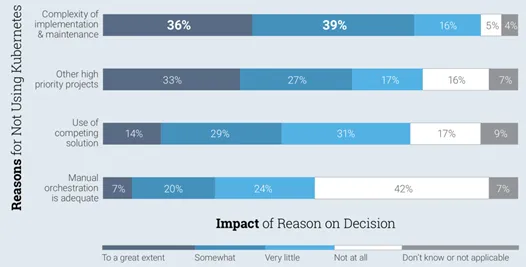
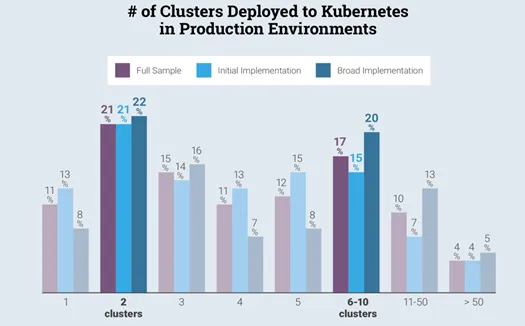
Another industry survey points out that the reasons for not using K8s for containers is because of its complexity of implementation and maintenance. The complexity is particularly acute if the clusters are implemented on existing VMware environments running inside the traditional datacenters with various storage backends and complex networking configurations due to legacy infrastructure setup. To add to the complexity, over a period of time, once the development teams are comfortable releasing production workloads on Kubernetes, the number of clusters tend increase to the tune of 10 clusters or more.
The Real Cost of DIY Enterprise Kubernetes Management
The following table details the amount of work involved in deploying a distributed infrastructure system based on Kubernetes along with a base level infrastructure monitoring, logging, backup and recovery, and security.
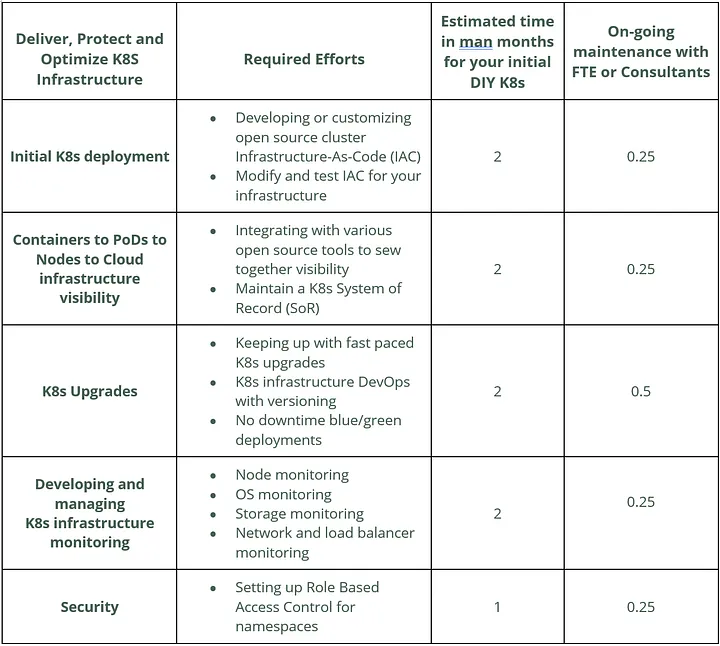
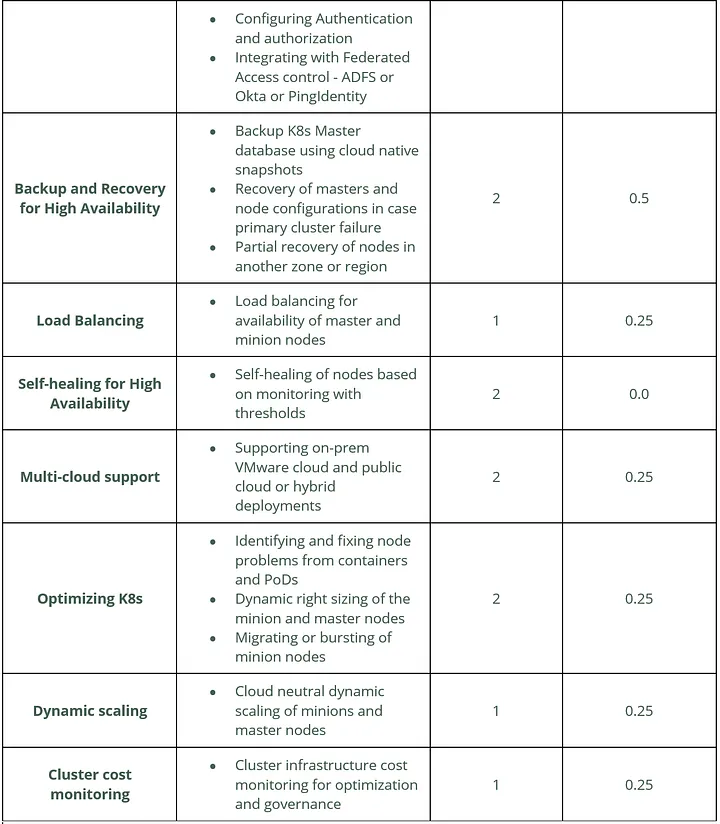
The Total Cost of DIY Kubernetes
The following table cost calculations are based on nominal DevOps consultants or fully loaded employee costs based in the USA. Also, these costs are calculated with an assumption that the teams operate between one to three clusters. For large installations, the costs could increase substantially based on the size of the clusters and type of integrations for add-ons, and integration with external systems.
Radically simpler Kubernetes with Appranix Site Reliability Automation (SRA)
Award winning Appranix platform offers a radically simpler alternative to deploying and managing Do-it-Yourself Kubernetes. Appranix reduces the time and effort required to deploy large,

high available clusters to mere hours as opposed to days and months. The platform currently offers three services based on the platform as shown in the Figure 4. Users can opt-in or out based on their requirements. The number of services will continue to increase based on requirements from customers and partners.
Appranix SRA Difference
Appranix is an industry first fully integrated platform focused on SRE teams. It is “application-centric” compared to other cloud or cluster operations tools that are “infrastructure-centric”.
Appranix is also the only platform that combines infrastructure release management, and backup & recovery, so maintaining high SLOs for clusters is much easier compared to Do-it-Yourself approaches. Finally, the only multi-cloud platform that seamlessly allows container, VM or PaaS based applications or microservices managed seamlessly in one service across multi-clouds.
Appranix SRA is Delivered as-a-Service
Appranix SRA is very easy to get started. Contact us to create an account to start with a Proof of Concept cluster deployed at your infrastructure provider of choice. All the K8s clusters created by Appranix Deliver Service, are CNCF certified with health checks.
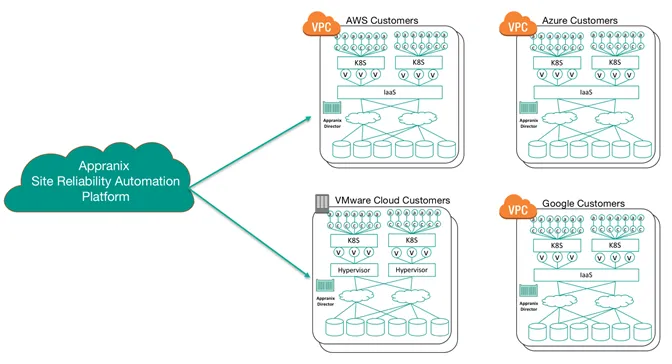
Deployed clusters can then be protected and optimized using Appranix Protect and Optimize Services.
Summary
Deploying and managing multiple large, high available, protected and optimized Kubernetes clusters are very hard and expensive. Appranix SRA radically simplifies the effort and cost of not only deploying the clusters but managing them effectively from development to staging to multiple production environments across multiple clouds.